|
Since we could use the operators available from the SQL provided in my previous post from Informatica, it could be translated easily into an Informatica map. The attached diagram is self explanatory. The SQL override specifies a sort order by col1. To get a predictable output every time with same data in the table, it could be sorted on col1 & col2 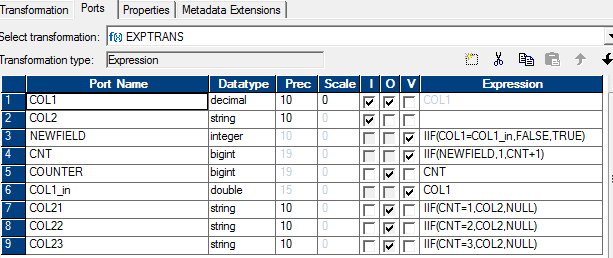 
0 Comments
When I was interviewed the approach I took was on these lines:-
SELECT col1, MAX(CASE WHEN rn = 1 THEN col2 ELSE NULL END ) col21, MAX(CASE WHEN rn = 2 THEN col2 ELSE NULL END ) col22, MAX(CASE WHEN rn = 3 THEN col2 ELSE NULL END ) col23 FROM (SELECT col1,col2,row_number() over (partition BY col1 order by col2) rn FROM test ) GROUP BY col1 The results were same as from the previous post Interviews are always fun, but some make them even more interesting by asking questions about things that you never really got to handle in practice, but you generally know the context. They test your ability to think on your feet, if not exactly, your knowledge... One such question I got was, how you would pivot a table with columns (col1 number & col2 varchar2) with data such that there are maximum 3 rows per a distinct value in col1, and the desired output is col1, col21, col22, col23. Whereas I have worked with pivoting data that could be aggregated, text data type for column col2 makes it more interesting. Here is one possible solution using SQL in Oracle database, create table test( col1 number(10), col2 varchar2(10)); insert into test values(1,'a'); ... insert into test values(3,'c'); commit; with t as( select col1, col2, row_number() over (partition by col1 order by col2) rn from test ) select a.col1, a.col2 col21, b.col2 col22, c.col2 col23 from ( select col1, col2 from t where rn = 1) a left outer join ( select col1, col2 from t where rn = 2) b on ( a.col1 = b.col1) left outer join ( select col1, col2 from t where rn = 3) c on ( b.col1 = c.col1) 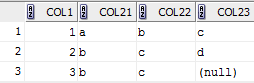 There won't be many times, but sometimes you may need to drop/recreate indexes on the CMX_ORS tables to typically re-import data. The following code PL/SQL code snippets shows how to do it.
Dropping Indexes CREATE OR REPLACE PROCEDURE drop_ors_indexes( in_table_name IN VARCHAR2) AS ddlText VARCHAR2(1000); CURSOR constraint_ IS SELECT t.table_name, replace(trim(k.rowid_key_constraint,'.','_')) rowid_key_constraint FROM C_REPOS_TABLE t, C_REPOS_KEY_CONSTRAINT k ON ( t.rowid_table = k.rowid_table AND t.table_name = in_table_name) WHERE EXISTS ( SELECT 1 FROM USER_INDEXES u WHERE u.INDEX_NAME = replace(trim(k.rowid_key_constraint,'.','_')); BEGIN FOR rec IN constraint_ LOOP ddlText := 'DROP INDEX '||rec.rowid_key_constraint; execute immediate ddlText; END LOOP; END drop_ors_indexes; / Re-creating indexes CREATE OR REPLACE PROCEDURE create_ors_indexes(in_table_name IN VARCHAR2) AS Left as an exercise for the reader to create based on drop indexes. You would need to use C_REPOS_KEY_CONSTRAINT_COL to use the columns for the index. Tablespace name is also available from the C_REPOS_TABLE. BEGIN END create_ors_indexes; / |
About Sarbjit ParmarA practitioner with technical and business knowledge in areas of Data Management( Online transaction processing, data modeling(relational, hierarchical, dimensional, etc.), S/M/L/XL/XXL & XML data, application design, batch processing, analytics(reporting + some statistical analysis), MBA+DBA), Project Management / Product/Software Development Life Cycle Management. Archives
March 2018
Categories
All
|
 RSS Feed
RSS Feed