|
A few weeks back got a chance to attend Oracle’s Real World performance tuning class. This class was using Exadata hardware and Oracle 12c edition. A very interesting set of findings that I would like to present here:-
0 Comments
Introduction A modern DBMS is necessarily a fairly complex system. The complexity arises from the fact that these systems need to abstract transaction management techniques from the application developers; need to provide simultaneous access to the database from multiple applications or users in timesharing and multiprocessing systems; and, usage of data caching or buffering techniques to provide fast access to frequently and recently used data. These systems could experience events(e.g. failures, conflicts) in hardware, software and media that could result in incomplete application of the data from a single transaction to the database, requiring recovery of the database. Recovery may also be necessary when certain user or programming errors result in un-intentional loss in data.
The recovery techniques vary widely according to the type of interruption and by the sophistication of the features provided by the DBMS. A failure in the last part of a transaction may require only an undo of the changes made to the database for the earlier parts of the transaction. A failure in media, however, may require shutdown of the database instance, recovery of media from a backup, and redoing the transactions which were committed before the failure happened and undoing the transactions that were in progress when the failure happened. In the database providing multi-versioning support, it might be possible to recover the data before the error happened. This report surveys literature describing the general techniques used for databases recovery and their relative merits and flaws and how the field has progressed over time. This report then describes how these techniques are being used in Oracle relational database management system. Literature Survey [Elmasri, Rameez 2007] provides an introduction to the concepts of transaction processing, desirable properties of transactions and operations required to realize transactions. It presents how multi-user systems could lead to incorrect data in the database if it allows uncontrolled execution of transactions. It also describes types of failures that happen during transaction processing. It discusses various steps in a transaction and some of the recovery and concurrency control mechanisms. It introduces to the concept of DBMS system log that keeps track of database access and how it could be used to implement recovery from failures. It also defines a schedule as an execution sequence of several transaction and characterizes schedules in terms of their recoverability. Of significance are recoverable schedules that make sure that once a transaction commits it never has to be undone. Cascade-less schedules require that an aborted transaction does not require aborting another transaction. Strict transaction schedules require that a DBMS be able to restore the old values of items that have been changed by an aborted transaction. If the nature of the failure, e.g. a disk crash, resulted in extensive damage to large parts of the database, then the recovery method uses a database that was backed up to archives and apply the transaction recorded in the system log up to the point of failure. However, when failure in transactions leaves the database in inconsistent state a combination of undo & redo of operations recorded in the system log would get the data in consistent state. Since DBMS has to handle large amount of data and disk access is costly, it buffers the data in memory and employs strategies to minimize the disk access, by using the buffers first. When a block is updated a dirty bit could be set for the block and when its time to write to the disk only dirty blocks are written. These modified blocks could be updated in-place i.e. at the original location on the disk or a shadow block could be written in a new place. When in place updating is used before image(BFIM) is written to the log and flushed to the disk before this block is overwritten by after image(AFIM) in the database and this is called UNDO entry. This process is known as write ahead logging. When the AFIM is also stored in the log it is called REDO entry. When a buffer block can’t be written to disk before the transaction commits, it is called a no steal approach, however, if the protocol allows writing the buffer before commit its called a steal(no pun intended). If all the buffer blocks updated by a transaction are written to disk before commit, its called a force approach, otherwise a no-force approach. A typical DBMS employs steal/no-force approach. With steal approach less RAM is required for storing buffer data and with no-force approach less i/o would be required as the same block could potentially be updated by another transaction. To facilitate recovery DBMSes keep a list of active, committed and aborted transactions and information about last checkpoints. DBMS’s recovery manager would write all the modified buffers at regular intervals (measured in terms of time or number of transactions) to the database. These writes are called checkpoints. After every checkpoint the DBMS writes an entry to system log. So in case of recovery the data blocks before the checkpoint don’t have to be redone. A checkpoint consists of the following actions: 1. Suspend execution of transactions temporarily. 2. Force-write all main memory buffers that have been modified to the disk. 3. Write a record to the log and force write the log to the disk. 4. Resume executing transactions. The checkpoint record may contain information about active transactions and their first and most recently modified records, this information would help with quicker undoing of any transactions that must be rolled back. However, large amount of data for step 2 could keep the transactions suspended for too long, so it a revised technique called fuzzy check-pointing may be used. In this technique the DBMS does not wait for the step 2 to finish, instead launch step 3 and allows the transactions to resume as soon as the checkpoint log is written. However, the log is in invalid state and it keeps a pointer to the last valid checkpoint long entry. Only after step 2 finishes, it makes the checkpoint log valid and move the pointer to new log record. Deferred update is a technique where actual changes to database are postponed till transaction completes its execution successfully and reaches commit point. The transaction reaches the commit point only after the update operations are recorded in the log and complete writing to the disk. It is also called a NO-UNDO/REDO recovery algorithm. In a single user environment the procedure involves keeping two transaction lists, one for the committed transaction since the last checkpoint and another one with active transactions. After a failure, read the committed transaction list after the last checkpoint and read the log file and apply the WRITE operations to the database; the active transactions would need to be re-started either by the user or recovery process. The redo operation should be idempotent – that is repeating it any number of times produces the same output. In multi user system the approach in intimately intertwined with the concurrency management approach. If the approach uses strict two-phase locking it ensures a strict and serializable schedule. The technique is essentially same as that described for the single user case, however, the changes(WRITE operations) are applied in the same order in which they were written to the system log. An improvement to efficiency of the algorithm can be made by applying only the last WRITE operation for item X to the database. The main benefit of this approach is that nothing has to be UNDONE. The main limitation is that it reduces the concurrency as the items need to be kept locked till the transaction reaches the commit point. There are two main categories of recovery techniques in case of Immediate Update to the database i.e. applying the changes to the database before the transaction has committed. In these techniques the update has to be recorded in the log file before it gets applied to the db using the write ahead protocol. This would help us undo the changes to the database in case of failed or rolled-back transaction. One of these techniques(UNDO/NO-REDO) assures that all the changes have been applied to the database and only then the transaction is committed. The other variation is to allow the transaction to commit before the changes to the database are made. The later technique is a more general case and is called UNDO/REDO, and its recovery procedure uses the same two transaction lists(committed since last checkpoint & active ones). First all the operations for active transactions are un-done in the reverse order in which they are written to the log. Then, all the write operations of the committed transactions are re-done. The later step could be optimized by applying on the last write operation for any item. This could be accomplished by walking the redo log in reverse order and keeping an ignore list of items that have already been applied to the database. Shadow Paging technique considers the database to be made of a number of fixed size blocks for recovery purposes. A directory for those blocks is constructed with ith entry in directory pointing to the ith block in the database. When a transaction begins the directory which points to the most recent database pages on the disk is copied to a shadow directory. The shadow directory is saved to the disk and the current directory is used for changes required by the transaction. The transaction never modifies the shadow directory. When some update to data block is performed the modified block is copied to a new location, however, the old copy stays. The current directory now points to the new block. To recover from a failed transaction the modified blocks are freed up and current directory is discarded. The shadow directory still point to the before image and is reinstated. Committing the transaction requires saving the current directory and discarding the shadow directory. As no work is required to be redone or undone this technique could be called a NO-UNDO/NO-REDO technique. With single users no logs are required, however, with multi-user environments requiring concurrent transactions the techniques incorporates system logs and checkpoints. This technique has limitations that updated database pages change location that makes the task of keeping related pages close harder. Large directories could require large RAM or paging to the disk, and also copying the shadow directories to disk is expensive. Another complication is to keep track of freed up resources when transaction commits. The operation to migrate between old and new directories should be atomic. The book also describes the ARIES algorithm which is reviewed as part of another paper review. It also describes the two-phase commit protocol that is used by multi-database systems. [Mohan, et.al. 1992] In this paper the authors introduce a novel method called ARIES (Algorithm for Recovery and Isolation Exploiting Semantics) for recovery in concurrent, transactional database management systems using write ahead logging while supporting partial rollback of transactions and fine grained locking strategies. It uses a variation on the UNDO/REDO protocol described above in the review of material from Elmasri,et.al’s book. It uses a transaction table that describes the transactions in flight and a dirty page table that describes the buffers in the pool that are yet to be written to the database. This protocol uses a a system log for recording the changes. It contains records for WRITE, COMMIT, ABORT, END and UNDO. Write record is written when a block is updated, commit, when the transaction is finalized, and abort when a transaction is cancelled. These operations are common to the other protocols described above. It also records a compensating log record when an UNDO operation happens and END is used when a transaction is done with COMMIT or ABORT operations. It uses a new concept of Log Sequence Number(LSN). LSN is a monotonically increasing number and points to the address of a record in the system log. Each of the buffers in the pool contains the LSN for the latest change in that block. Another feature of this protocol is check-pointing. When check-pointing is done a dirty page and transaction table structures are written to the disk. That means that data does not have to be flushed to the disk. Recovery according to this protocol is three stepped approach. First step is Analysis, which starts with the last checkpoint and starts with the begin_checkpoint record and then proceeds towards the end. It reads the recovery data structures(dirty pages & transaction table) and applies the appropriate changes from the records and records the appropriate LSN. Second step is REDO. This step works efficiently by reading the dirty table records and noting the lowest LSN and highest LSN. Lowest SCN marks the start point for writing the data to the database and the highest LSN marks the end of required REDO. When REDO is done, UNDO can start by looking at the active transactions and apply the before images by walking backward from the end of the system log. It writes a Compensating Log Record(CLR) when an UNDO operation is finished, so that the same operation is not performed again in case there was a server crash in the middle of db failure. [Agrawal, Dewitt 1985] This paper presents analysis of the behavior and performance characteristics of concurrency control and recovery mechanisms. Since the concurrency control and recovery mechanisms are closely associated, this paper analyzes the performance of these mechanisms in an integrated manner for their application to multi-user, transaction oriented centralized database management systems. The authors conclude: The choice of the “best” integrated concurrency control and recovery mechanism depends on the database environment. If there is a mix of transactions of varying sizes, log+locking emerges as the most appropriate mechanism. If there are only large transactions with only sequential access pattern, the shadow+locking mechanism is a possible alternative. In an environment of medium and large sized transactions, the differential+locking is a viable alternative to the log+locking mechanism. The authors also compare the optimistic concurrency control and locking with deadlock detection and conclude that “with the optimistic approach, not only are there a higher number of transaction restarts, but each restart is also more expensive” and that “optimistic method of concurrency control should only be considered in an environment where transactions are small with a very low probability of conflict”. When comparing the recovery mechanisms they recommend the usage of undo with logging, even though its more expensive than shadow or differential files, because, “logging puts a smaller burden on a successful transaction” and “most of the transactions succeed rather than abort” [Verhofstad, 1978] is the earliest work on summarizing the various techniques used for “recovery, backing out, restarts, maintenance of consistency and crash resistance” in filing systems, databases and operating systems, with the focus being on database management systems. It categorizes these techniques, presents the basic principles and the situations where they could be applied. It also provides how these techniques were applied in the systems contemporary to the time when this paper was written. I have chosen not dwell on the individual techniques as they have been covered elsewhere in this survey. However, it is mentioned here as one of the earliest works and its usefulness in clarifying the concepts. [Elhardt, Rudolf 1984] is one of the earliest works that demonstrates the importance of a database cache for high performance and quick restarts in databases. The database cache is demonstrated to be highly effective in applications that require high throughput of short transactions. Per this paper the db cache holds the frequently accessed pages, those pages can be changed without traffic to the database. So it is easier to not store the before images of the unfinished transactions on the database. It states that the commit processing is very fast because of sequential output of the after images to the safe. Transaction failures don’t have to touch the database, but instead could be handled on the cache itself. It provides for a fast restart of the database after a failure. It also supports sophisticated lock protocols with concurrent reading and writing. This paper also recognizes the need to support longer running transactions and long update transactions. They only require cache support for fixed pages. The secondary storage required to keep the recovery information is proportional to the update activity, but not tied to the length of transaction per se. It allows the commit and abort processing to be serialized with other TAs and therefore need not be fast. [Lau, Madden 2006] represent an novel approach to providing high transactional output and fast recovery in distributed data warehouses. Their approach assumes that distributed databases are used for providing high availability. They show how the data redundancy could be used to approach recovery in such an environment. Their approach does not use a stable log and provides recovery without quiescing the system. Traditional data warehouses are built mostly to provide read access to historical data gathered from the operational database systems. They usually use bulk loads of data instead of insert/update activity and did not require the usage of traditional recovery and transactional control semantics. However, the trend in data warehouses is to provide more frequent inserts and sometimes even updates of data for missing or incorrect data. This updatable data warehouses require the databases to provide both recovery and transaction support. Their approach is called HARBOR (High availability and replication based online recovery). Its based on a requirement that such a system have some form of replication to support high availability. They show how to exploit this redundancy to provide efficient crash recovery without the use of a stable log, forced writes during commit or complex recovery techniques like ARIES. Their approach is flexible in that it does not require the replicated version of data to be stored in identical format, as it possible to store that data in different formats so that optimizer could use different storage characteristics to partition the workload to use the format that provides fastest response or highest throughput. Data warehouses workloads have high number of ad-hoc queries over large datasets mixed with small amount of OLTP transactions to correct problems with the data. So to avoid contention a technique of snapshot isolation is used. Their approach is similar and uses timestamped(insertion and deletion at each tuple level) and versioned representation of data to isolate reads. Timestamps are written at the time of commit, and a 0 in deletion timestamp says that the tuple is not deleted. Historical queries read data as of past time and the timestamps allow isolation of read data from the most recent update transactions. Their model assumes K safety(i.e. database is still available if k sites fail) is provided by the database designer using data replication. The recovery algorithm consists of three phases. The first one is to use the checkpoint mechanism to determine the most recent time(T) up to which the updates/inserts have been flushed to the disk. Historical queries provide the updates that were made to the database after T and will be applied to the local database of recovering site. A standard dirty pages table with the identity of all in memory pages with modified flags. Check-pointing consist of taking snapshots of the dirty pages table and then taking latches on the dirty pages and flushing them to the disk. After all these blocks have been flushed the time T is recorded to a well known location on the disk. In second phase the recovering site executes historical queries on remote sites that contain replicated data to bring the missed updates and get current. The use of historical queries avoids read locks and therefore quiesce the system during recovery of large amounts of data. The third phase uses read locks to catch up with any transactions that were committed since the start of phase two and current time. The coordinator keeps a queue of update requests, that would be forwarded to the crashed site so that it could join the ongoing transactions. The authors show how their algorithm surpasses the performance of ARIES algorithm. [Tukka et.al. 2008] present a survey of current and proposed work in using various multi-version index structures. As the databases are moving towards providing multiple versions of database items for running historical queries as well as providing audit ability, they need to have special structures for storing the data to handle query time and space constraints. There are a large number of these structures that have been made available, however, the authors are not satisfied with the concurrency control and recovery methods available for those structures. They compare the pros and cons of using standard B+ tree structures, R-tree structures, multi-version B+ trees, and time split B+ trees for providing single and multiple versions of the data. Multi-version B+ trees don’t provide comprehensive concurrency control. Time split B+ trees provide concurrency control and recovery methods, but don’t provide space efficiencies. They are interested in designing modified versions of these structures so that more comprehensive concurrency control and recovery could be provided and compare and contrast their results for each of these implementations. They describe that their recovery methods would be based on the de facto standard ARIES algorithm. They describe that their version of read only transactions would implement the operations:- begin_read_only, query(key,version), range query( range [k1,k2], version v ), commit read only. An updating transaction will not provide a version number in its actions, so a multi-version concurrency control algorithm will be applied to maintain serializable view of the most recent version of the database for reach transaction. They discuss the use of lazy time-stamping techniques[Torp, et.al. 00] for implementing the version control. To implement the update transactions the plan to implement the following operations:- begin_update, query(key), range query( range [k1,k2]), insert( key k, data w), delete(key k), commit-update, abort, undo-insert(log record r), undo-delete(log record r), finish-rollback. [Lahiri et.al 2001] discuss a very important applied aspect of recovery algorithms when it comes to Oracle database server. The discuss an implementation of important high availability feature of Oracle trademarked as Fast-Start Fault recovery that allows the users to impose predictable bounds to the time required for recovering a crashed database. Oracle supports a shared disk architecture and a typical database configuration consists of one or more Oracle instances(user and oracle processes and memory structures) accessing shared set of data files that constitute the database. Each instance has its own buffer cache and different caches are kept in synch with through a distributed lock management protocol. This architecture in Oracle is known as OPS(oracle parallel server) or RAC(real application clusters) in more recent versions. Each instance has its own set of REDO log files and the changes made by transactions to the buffers in cache(also known collectively as SGA) are recorded to the log file for the instance. They describe the log as ever increasing sequence of bytes indexed by Redo Byte Address(RBA). The recovery begins from a Thread Checkpoint RBA and ends with and RBA called Tail. Each transaction is assigned a Rollback Segment where it records the changes made by the transaction to the database and will be used if a rollback of the transaction is required. When a change is made to a buffer in cache, redo records are written to the log file atomically for the changes both to the buffer as well as to the Rollback Segment. Oracle uses a version based concurrency system known as Consistent Read. Every transaction is associated with a snapshot time. When it reads a block in buffer it first reconstructs the image of data as of the snapshot time. It uses the undo data stored in the rollback segments. This allows reading the data without the use of locks. Reads/writes don’t block each other. In Oracle only writers need to use locks. These locks are stored within the blocks of data for each of the rows and are persistent as they can be recovered from the REDO following a crash. In OPS cluster whenever an instance discovers that another one has failed it first suspends access to the database and then rolls forward the changes in failed instance’s REDO thread from the last checkpoint to the tail of the log. After the roll forward the database is opened for normal online processing. Meanwhile the SMON process applies the UNDO from the rollback segment for any transactions that were in flight at the time of failure. The time taken for roll forward is determined by the REDO log I/Os and Data file I/Os. The former being the number of blocks between the checkpoint and its tail, and the later being the number of data blocks that were modified but were not written to the database. This size is controlled by the periodicity of check pointing. Dirty buffers are kept in a Buffer Checkpoint Queue in ascending order of the RBA of the first change to the buffer. Writing buffers in the low RBA order advances the checkpoints. Periodic write the database writers to advance the checkpoint is called Fast Start Checkpointing. While conventional checkpointing is exhaustive the one implemented by this approach is incremental, writing only those many buffers as are needed to advance the thread to required position in the log. Oracle allows the database administrators to specify three dynamic configuration control parameters for controlling the rate of checkpointing. They describe the parameters as: FAST_START_IO_TARGET: This parameter specifies a bound on the number of blocks that would need recovery at any given time on a running system. These blocks require random read and write IOs and dominate the roll-forward time. If an administrator believes that the I/O subsystem can perform approximately 1000 random IOs per second, she should set “FAST_START_IO_TARGET = 50000” to limit roll-forward time to approximately 50 seconds. LOG_CHECKPOINT_TIMEOUT: This parameter specifies a bound on the time elapsed since the tail of the log was at the position presently indicated by the thread checkpoint position. For example, setting “LOG_CHECKPOINT_TIMEOUT = 100” implies that the thread checkpoint should lag the tail of the log by no more than the amount of redo generated in the last 100 seconds. Since the time it takes to generate a certain amount of redo is approximately the same as the time it takes to apply that redo, LOG_CHECKPOINT_TIMEOUT may be interpreted as an upper bound on recovery time. It is an upper bound since workloads typically contain a query component that does not generate any redo. LOG_CHECKPOINT_INTERVAL: This parameter bounds the number of redo blocks between the thread checkpoint and the tail of the log. This parameter therefore imposes an upper bound on the number of redo blocks that need to be processed during roll-forward. Oracle provides another mechanism called Fast Start Rollback for quicker recovery. As Oracle keeps its lock information in the data blocks itself, database could be opened to new transactions while the rollback is in progress. It provides two mechanisms to make the rollback fast. It parallelizes the rollback of uncommitted transactions and also provides on demand rollback. Oracle uses inter and intra transaction parallelism algorithms to make the rollback faster. When there are a large number of transactions for requiring rollback, each of them could be rolled back in parallel. Sometimes large transactions could be broken into partitions of independent work and scheduled for rollback in parallel. It uses FAST_START_PARALLEL_ROLLBACK to control the number of threads that would be used for perform parallel recovery. On demand rollback mechanism uses the ability of Oracle to rollback those blocks that are required by other transactions for reading, etc. It uses the rollback segments to provide the data required by consistent reads and therefore could use the same facts to recover those blocks at a time earlier than it would be done normally and this extra work of reading redo to provide consistent image won’t have to be done time and again. Applications This survey was done with the goal of understanding the role of recovery in databases. Most of the commercial systems provide recovery capabilities at various levels. These recovery capabilities provide a lot of benefits from integrity of the database to high availability. However, these benefits come at significant cost. A large amount of work has been done to come up with the most efficient algorithms for making the recovery quickly. The researcher has been involved in both transactional and data warehousing systems. He appreciates the application of technology in the OLTP domain. He, however, struggled quite a bit by the limitation imposed by these mechanisms where automated recovery by the database might not be the most efficient way to handle recovery for all objects in the database. [Lau et. Al. 2006] refer to the similar goals. Whereas databases like Oracle provide the ability to make the objects no logging, i.e. without the ability to roll forward any changes from the last back up, they don’t provide the ability to not use rollback segments, to the best of researcher’s knowledge. For large transactions this is a problem, when neither the ability to roll forward or rollback is require because it would be more efficient to provide the recovery by the loading mechanism itself and the business might be open to not having the latest data available everyday due to the very nature of data warehouses. They may be able to live with the restore from the last back up from a few days ago and allow the load of data from the source system. There was definitely a need felt for making this tradeoff. Traditional database administrators are not used to supporting large data updates and may not size the ROLLBACK segments(or equivalent terms in different databases, e.g. UNDO table space in more recent versions of oracle) for handling those transactions and balk at providing the required disk space. This may lead to a large number of transaction failures requiring large rollbacks and therefore extra work in the database. However, given a database, and a better understanding of the mechanisms used for recovery, it would lead to better application architecture. Summary This survey paper was intended to get a better understanding of the concepts and algorithms available for recovery mechanisms. Since no particular order was followed for understanding the concepts, the chronological order was not maintained due to the constraints on time. However, a large number of these concepts were explored and progression of algorithm sophistication was observed. ARIES was observed to be a benchmark algorithm in sophistication and most of the current databases seem to use a variation on this algorithm for their own implementations. However, most of these traditional algorithms are not necessarily most optimal in case of large data set based updates. Research seems to be leading to addressing some of these concerns. Another focus of the recent research has been to improve the ability of the databases to provide multi-versioning of the datasets, when the requirements from watch dog agencies for providing the auditable changes and also to address security concerns with malicious data updates. Lastly, the project also explored the application of these algorithms in Oracle database by reviewing the work done for providing its FAST-START feature set. Works Cited Elmasri, Rameez and Navathe, Shamkant. Fundamentals of Database Systems. Boston: Addison Wesley, 2007. Mohan, C., Haderle, D., Lindsay, B., Pirahesh, H. and Schwarz, P “ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging” ACM Transactions On Database Systems, Vol. 17, No. 1, March 1992: 94-162. Verhofstad, J. “Recovery Techniques for Database Systems” Computing Surveys June 1978: 167-195. Agrawal, R. and Dewitt, D. J. “Integrated Concurrency Control and Recovery Mechanisms: Design and Performance Evaluation” ACM Transactions On Database Systems, Vol. 10, No. 4, December 1985: 529-564. Elhardt, K. and Bayer, R. “A Database Cache for High Performance and Fast Restart in Database Systems” ACM Transactions On Database Systems, Vol. 9, No. 4, December 1984: 503-525. Lau, E. and Madden, S. “An Integrated Approach to Recovery and High Availability in an Updatable, Distributed Data Warehouse” VLDB’06, September 12-15, 2006, Seoul, Korea. Haapsalo,T., Jaluta, I., Sippu, S., and Soisalon-Soininen, E. “Concurrency Control and Recovery for Multi-version Database Structures” ACM Workshop of PIKM08, October 30, 2008, Napa Valley, California, USA. Torp, K., Jensen, C., and Snodgrass, R. “Effective timestamping in databases” The VLDB Journal- The international Journal on Very Large Data Bases,8(3-4), 2000: 267-288. Lahiri, T., Ganesh, A., Weiss, R., and Joshi A. “Fast-start: Quick Fault Recovery in Oracle” ACM SIGMOD, May 21-24 2001: Santa Barbara, California, USA. When doing a code review one looks to see if the best practices are followed. Some are about the readability and therefore maintainability of the code, but, then there are some which could point to application logic traps. While reviewing a SQL I found something in production code, leading me to believe it could/should have been caught more easily with a code review itself, though there is no excuse that it was not found with the data validation/qa step.
The pattern is as following:- Select grouping_attribute , max(descriptor_type_attribute), max(attribute_expiry_date) From table Group by grouping_attribute The data has to do with licensing of certain professionals, and the descriptor_type_attribute is the identifier given by the licensing board and will have any expiry date associated with it. This query would have been fine if both the attributes followed the same sorting strategy, but it was not the case. So one could end up picking up a license number(descriptor_type_attribute) with wrong expiry date. Not the intended outcome. Part of the fault in my humble opinion lies with giving a _no postfix to the descriptor_type_attribute in the data model. A better query could be written using the analytical functions in Oracle, e.g. Select grouping_attribute, descriptor_type_attribute, attribute_expiry_date from ( Select grouping_attribute, descriptor_type_attribute, attribute_expiry_date, Row_number() over(partition by grouping_attribute order by attribute_expiry_date desc) rn From table ) q Where q.rn=1 Continued from Columnar Databases I ...
So if a situation allows us to live with the limitations of the columnar databases, how good are columnar databases. To find out for myself I set up an experiment to compare a popular row based database (Oracle 11g) with compression turned on with a columnar database (Infobright) that relies on an open source database engine (MySQL). I also set the experiment to mainly explore the compression in storage, rather than any query performance as I did not have resource to set up that elaborate an experiment. For OLTP data structures(TCP-H(tm) Bench Mark) the Oracle compressed row data store used about 10 GB storage including some indexes, which are required for such databases. Infobright database on the other hand showed a 1.9GB. This is about 1/5th the storage required. This is a significant saving, when there are not a lot of indexes in row store, and if more indexes were added for performance reasons it would have shown even better comparison on storage requirements. For Star Schema Bench Mark database, the data extracts were of the range of 6.7 GB of raw ASCII data, when pulled from Infobright (it by default provides quoted strings, etc) vs. about 6 GB of raw ASCII data when pulled from Oracle tables, using custom pipe delimiter. When loaded into Infobright it compressed the data into a size of about 800MB, again using no indexes. When loaded into Oracle database with the same compression scheme as before the data used about 6.5GB. From these observations, we conclude that while Oracle provides compression, considering that we had 3 large indexes on the lineorder, and smaller indexes on smaller tables as well. However the columnar database (Inforbright) provided an order of magnitude compression compared to the raw text data and row store's (Oracle) equivalent database with basic compression. Due to lack of appropriate storage (exadata machine) I could not test the more aggressive compression scheme available from Oracle row store database. Query timings were better in case of Infobright database where the large fact table extraction to flat file took about 12 minutes and in case of Oracle the same took about 42 minutes. Thus highlighting the benefits of smaller storage, at the least, as the queries did not use any index for Oracle either as these queries gets all the data from the tables in the join. The star schema shows a higher compression ratio for the columnar database, even though, it uses mainly numeric type data types in the large fact table. References:- Abadi, D., Boncz, P., Harizopoulos, S. "Column-oriented Database Systems" in VLDB ’09, August 24-28, 009, Lyon, France. Abadi, D.J., Madden, S.R., and Ferreira, M. "Integrating compression and execution in column-oriented database systems" In Proc. SIGMOD, 2006. Hodak, W., Jernigan, Kevin, "Advanced Compression with Oracle Database 11g Release 2" An Oracle White Paper from Oracle corporation, September 2009 Oracle, "Oracle 11g SQL Reference Guide" from otn.oracle.com Oracle, "Oracle 11g Utilities Guide" from otn.oracle.com Inforbright.org, "Direct data load guide" available from inforbright.org With the need for processing more and more data and also the availability for more data captured electronically from various data collection points through commercial, non-profit, government or research communities. This phenomenon is termed as Big Data in industry parlance. To make sense out of
this data being gathered it requires large amount of processing power. This data may be available in granular form or as documents, and sometimes both may be co-related. Over the period of time we notice that the nature of the data gathered is getting changed. Traditionally most of the data was transactional in nature, requiring CRUD(create, update, delete) operations. Now a larger amount of data is being created that is usually not updated and may only be deleted when it is no longer needed, usually after a longer period of time than in the transactional sense. While OLTP database provided the ability to store the CRUD operations with ACID(atomic, consistent, isolated and durable) properties for handling more granular data, they were then enhanced to add storage of various types of documents(text, pictures, etc.) again with the OLTP type of transactions in mind. These databases typically use a normalized data model for storage. But the need for providing ACID guaranties, and to handle different type of data volumes for analytical needs, the data could no longer be contained in those models. Therefore the data warehouses were designed using same type of databases, but with different type of data models (typically dimensional, though not always). Data warehouses allowed separation of data from the OLTP systems, but still grew fairly large in volumes, and typically serve more read type operations than frequent updates or writes. While working with large volumes of data, I noticed that at times a large number of columns in a table have low cardinality, but the overall size of the table itself may be fairly large. This led me to believe that one could reduce the size of the data as stored on the disk if compression techniques are used. Since disk access is usually the slowest part of the access of a database a smaller footprint of data would presumably lead to faster retrieval of the data from the slower medium, however, there would be associated CPU cost that would be incurred in compressing the data. Since data warehouses carry the largest amounts of data there presumably would be tradeoff scenarios in using one or the other technique. Even though the normalization theory is about reducing the redundancy of duplicate data, and therefore providing most efficient storage, there has to be other techniques that could be combine with this to reduce the overall query timing. One of the recent technologies that focus on this aspect is the columnar storage based databases. [Abadi, Boncz, Harizopoulos, 2009] provide a brief introductory, tutorial to the columnar databases. They describe the columnar databases as "Column-stores, in a nutshell, store each database table column separately, with attribute values belonging to the same column stored contiguously, compressed, and densely packed, as opposed to traditional database systems that store entire records (rows) one after the other." They trace the history of the column stores back to 1970s, when the usage of transposed files were explored. In 1980s the benefits of decomposed storage mode(DSM) over row based storage were explored. Its only in 2000s that these data stores finally took off. Because of the affinity of the data values stored contiguously on disk pages for each of the columns the data lends to better compression schemes, that may be light weight in their CPU utilization but still provide heavy compression. However, these databases are challenged in their ability to provide updates and also in tuple construction required for use in applications which access data through ODBC/JDBC type interfaces. The tuple construction is required to present the data in row format used by these access applications. Continued at Columnar Databases II Since we could use the operators available from the SQL provided in my previous post from Informatica, it could be translated easily into an Informatica map. The attached diagram is self explanatory. The SQL override specifies a sort order by col1. To get a predictable output every time with same data in the table, it could be sorted on col1 & col2 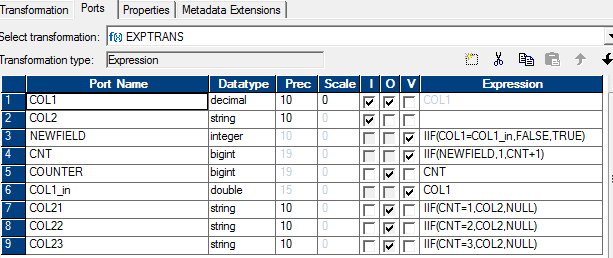  When I was interviewed the approach I took was on these lines:-
SELECT col1, MAX(CASE WHEN rn = 1 THEN col2 ELSE NULL END ) col21, MAX(CASE WHEN rn = 2 THEN col2 ELSE NULL END ) col22, MAX(CASE WHEN rn = 3 THEN col2 ELSE NULL END ) col23 FROM (SELECT col1,col2,row_number() over (partition BY col1 order by col2) rn FROM test ) GROUP BY col1 The results were same as from the previous post Interviews are always fun, but some make them even more interesting by asking questions about things that you never really got to handle in practice, but you generally know the context. They test your ability to think on your feet, if not exactly, your knowledge... One such question I got was, how you would pivot a table with columns (col1 number & col2 varchar2) with data such that there are maximum 3 rows per a distinct value in col1, and the desired output is col1, col21, col22, col23. Whereas I have worked with pivoting data that could be aggregated, text data type for column col2 makes it more interesting. Here is one possible solution using SQL in Oracle database, create table test( col1 number(10), col2 varchar2(10)); insert into test values(1,'a'); ... insert into test values(3,'c'); commit; with t as( select col1, col2, row_number() over (partition by col1 order by col2) rn from test ) select a.col1, a.col2 col21, b.col2 col22, c.col2 col23 from ( select col1, col2 from t where rn = 1) a left outer join ( select col1, col2 from t where rn = 2) b on ( a.col1 = b.col1) left outer join ( select col1, col2 from t where rn = 3) c on ( b.col1 = c.col1) 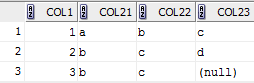 There won't be many times, but sometimes you may need to drop/recreate indexes on the CMX_ORS tables to typically re-import data. The following code PL/SQL code snippets shows how to do it.
Dropping Indexes CREATE OR REPLACE PROCEDURE drop_ors_indexes( in_table_name IN VARCHAR2) AS ddlText VARCHAR2(1000); CURSOR constraint_ IS SELECT t.table_name, replace(trim(k.rowid_key_constraint,'.','_')) rowid_key_constraint FROM C_REPOS_TABLE t, C_REPOS_KEY_CONSTRAINT k ON ( t.rowid_table = k.rowid_table AND t.table_name = in_table_name) WHERE EXISTS ( SELECT 1 FROM USER_INDEXES u WHERE u.INDEX_NAME = replace(trim(k.rowid_key_constraint,'.','_')); BEGIN FOR rec IN constraint_ LOOP ddlText := 'DROP INDEX '||rec.rowid_key_constraint; execute immediate ddlText; END LOOP; END drop_ors_indexes; / Re-creating indexes CREATE OR REPLACE PROCEDURE create_ors_indexes(in_table_name IN VARCHAR2) AS Left as an exercise for the reader to create based on drop indexes. You would need to use C_REPOS_KEY_CONSTRAINT_COL to use the columns for the index. Tablespace name is also available from the C_REPOS_TABLE. BEGIN END create_ors_indexes; / |
About Sarbjit ParmarA practitioner with technical and business knowledge in areas of Data Management( Online transaction processing, data modeling(relational, hierarchical, dimensional, etc.), S/M/L/XL/XXL & XML data, application design, batch processing, analytics(reporting + some statistical analysis), MBA+DBA), Project Management / Product/Software Development Life Cycle Management. Archives
March 2018
Categories
All
|
 RSS Feed
RSS Feed