|
A typical Informatica MDM implementation uses Informatica ETL tool for processing data to the Landing tables, and may have one or more stages, depending on the architecture, for processing data from various in house or third party data providers; processing from Landing to Staging to Various target tables(cross reference, and associated tables), tokenization of these records and then match merge in the Informatica MDM space; and then generating feeds to various downstream data marts, data warehouses, OLTP systems, and third parties. In my experience a majority of this work happens with the Powercenter and MDM toolsets from Informatica. Though in this realm work can be and is done using Web Services, but for the purpose of this article, I shall ignore that use case. Once a system is in place, it needs to be monitored for ensuring ongoing data quality and performance. This tends to be a tedious task because not only are there multiple stages to the whole processing before, during and after MDM processing of the data, but also the performance metrics are stored in two different repositories. This article show what data is available in those repositories and how one could set some naming patterns as part of the standards while architecting such a system that would make it not only possible, but approach the whole effort in an efficient manner. So let us explore what both the repositories provide, starting with Informatica Powercenter repository:- Powercenter repository provides and can be leveraged to get a multitude of reports as shown here. For the purpose of this blog I shall be using the following tables:- a) opb_task_inst b) opb_task_run_inst The first table could be queried to get the various workflows/worklets/sessions that are available in the repository. I use the following query to get the information about the workflow and the other artifacts contained therein in a hierarchical fashion. WITH session_cfg_info AS (SELECT * FROM (SELECT connect_by_root workflow_id the_workflow_id , Sys_connect_by_path (task_id, ',') full_task_id, ti.*, Sys_connect_by_path (instance_name, '/') fully_qualified_name FROM (SELECT * FROM opb_task_inst ta WHERE task_type <> 62 AND version_number = (SELECT Max (version_number) FROM opb_task_inst ti2 WHERE ti2.instance_id = ta.instance_id)) ti WHERE connect_by_isleaf = 1 START WITH ti.workflow_id IN (SELECT task_id FROM opb_task WHERE task_type = 71) CONNECT BY PRIOR ti.task_id =ti.workflow_id) q WHERE q.task_type <> 70), workflow_cfg_info AS (SELECT subject_id, task_id the_workflow_id, task_name FROM (SELECT subject_id, task_id, task_name, Row_number () over ( PARTITION BY subject_id, task_id ORDER BY version_number DESC) trn FROM opb_task WHERE task_type = 71) q WHERE q.trn = 1) SELECT f.subj_name folder_name, w.the_workflow_id ||full_task_id full_task_id, '/' ||w.task_name ||s.fully_qualified_name task_name, s.instance_name, s.instance_id, s.task_id FROM session_cfg_info s join workflow_cfg_info w ON ( s.the_workflow_id = w.the_workflow_id ) join opb_subject f ON ( f.subj_id = w.subject_id ) We shall come to the use of this result set later. Next we gather the run time information about various jobs that ran using the following query as a starting point. SELECT workflow_id, rn, workflow_run_id, worklet_run_id, child_run_id, task_id, instance_id, instance_name, workflow_id || SYS_CONNECT_BY_PATH (task_id, ',') full_task_id, start_time, end_time, SYS_CONNECT_BY_PATH (instance_name, '/') fully_qualified_name, run_err_code,run_err_msg,run_status_code,task_type FROM (SELECT workflow_id, workflow_run_id, worklet_run_id, child_run_id, task_id,instance_id,instance_name,start_time,end_time, run_err_code, REPLACE (run_err_msg, CHR (10), ' ') run_err_msg, DECODE (run_status_code, 1, 'Succeeded', 2, 'Disabled', 3, 'Failed', 4, 'Stopped', 5, 'Aborted', 6, 'Running', 15, 'Terminated', 'Other' ) run_status_code, task_type, CASE WHEN child_run_id = 0 THEN -1 * (ROW_NUMBER () OVER (ORDER BY end_time, start_time) ) ELSE child_run_id END rn FROM opb_task_inst_run t WHERE task_type <> 62) q WHERE CONNECT_BY_ISLEAF = 1 CONNECT BY NOCYCLE PRIOR rn = worklet_run_id AND PRIOR workflow_run_id = workflow_run_id START WITH worklet_run_id = 0 Joining this information with the data from the opb_sess_task_log table, the opb_wflow_run tab and opb_subject table, one can derive the information to be able to join with the data from the workflow configuration data derived in the first query above. One has to be careful as the opb_sess_task_log will have higher cardinality than the workflow run query provide immediately above. If I am trying to monitor things at each and source qualifier or target level it, we could join it directly. However, if one is just trying to get a ball park idea of the volumes processed it might as well be aggregated, and that may provide good enough information for trending the performance numbers. For this exercise let us go with the latter:- SELECT workflow_run_id,instance_id, SUM (src_success_rows)src_success_rows, SUM (src_failed_rows) src_failed_rows, SUM (targ_success_rows) targ_success_rows, SUM (targ_failed_rows) targ_failed_rows, SUM (total_trans_errs) total_trans_errs FROM etl_prd_rep.opb_sess_task_log tl GROUP BY workflow_run_id, instance_id So having discussed the Powercenter repository queries, let us review the provided results. If your implementation is like any that I have seen at multiple organizations, you would find that the sessions running MDM job stored procedures are reporting either 1 or 0 rows processed, depending on how the stored procedure is being called. This just ends up giving the run timings. If you are lucky the implementation may even record error when the MDM job fails. But, the number of rows are not reported back. So to address this deficiency, let us move on the MDM repository schema. Here the queries are straight forward to obtain information about various jobs: SELECT jc.rowid_job job_run_id,jc.system_name data_system, jc.table_display_name subject_table_name,jc.object_desc job_desc, (SELECT job_status_desc FROM c_repos_job_status_type WHERE job_status_code = jc.run_status)run_status,status_message, (SELECT object_function_type_desc FROM c_repos_obj_function_type WHERE object_function_type_code = jc.object_function_type_code) job_type, jc.start_run_date start_date, jc.end_run_date end_date, jn.total_records, jn.inserted_records, jn.updated_records, jn.no_action_records, jn.matched_records, jn.updatedxref_records, jn.rejected_records, jn.tokenized_records FROM c_repos_table t JOIN c_repos_job_control jc ON (t.rowid_table = jc.rowid_table) LEFT OUTER JOIN (SELECT rowid_job, MAX (CASE WHEN metric_type_code = 1 THEN metric_value ELSE NULL END ) total_records, MAX (CASE WHEN metric_type_code = 2 THEN metric_value ELSE NULL END ) inserted_records, MAX (CASE WHEN metric_type_code = 3 THEN metric_value ELSE NULL END ) updated_records, MAX (CASE WHEN metric_type_code = 4 THEN metric_value ELSE NULL END ) no_action_records, MAX (CASE WHEN metric_type_code = 5 THEN metric_value ELSE NULL END ) matched_records FROM c_repos_job_metric jm GROUP BY rowid_job) jn ON (jc.rowid_job = jn.rowid_job) Again I chose to report the statistics in a row, but decided not to aggregate as that won’t always make sense to add these numbers. Also, I am showing only a few stats in the query, other metrics are available as well. Now, we come to the real challenge. The challenge lies in being able to combine the rows from the Informatica repository with those from the MDM repository. One could follow the approach whereby one could create characterize the data pulled from both the repositories with common attributes. Here we go back to the purpose of the very first query from this article. We could e.g. gather that data in a table where we could add extra attributes that would help us characterize those sessions/jobs. We would follow a similar approach in case of the MDM data. We would need to make sure that whenever we add new jobs on ETL/MDM side that we add those rows to these characterization tables. Using these characterization tables and knowing the fact that on a reasonably time synchronized platform the ETL jobs timing would be same or a little outside the MDM job timing, we could combine the rows exactly and get all the relevant stats from the MDM system. On a multi-domain MDM system the following attributes would be sufficient:- a. Domain (Customer/Product) b. Source System (Admin or others..) c. Operation (Landing, Staging, Loading, Auto Match & Merge, etc.) d. Table Name or MDM Target Object. For joining the ETL run information with the configuration don’t forget to use the fully qualified task id, as that takes care of the various shared objects use in multiple parent objects. While building one such system, I was able to use the various patterns in names to find these attributes. Since, I approached this problem after the fact of building the system in first place, this task was not trivial, but was made easy by a consistent use of naming conventions. If I was leading the build process I think this task can be further simplified, and can be more easily incorporated into the initial build itself.
1 Comment
While configuring Informatica MDM 9.5.1, I ran into this exception which was found in the log file cmxserver.log.
Caused by: org.jgroups.ChannelException: failed to start protocol stack at org.jgroups.JChannel.startStack(JChannel.java:1617) at org.jgroups.JChannel.connect(JChannel.java:429) at org.jboss.cache.RPCManagerImpl.start(RPCManagerImpl.java:371) ... 93 more Caused by: java.lang.Exception: problem creating sockets(bind_addr=/*.0.0.*, mcast_addr=230.1.1.1:46000) at org.jgroups.protocols.UDP.start(UDP.java:389) at org.jgroups.stack.Configurator.startProtocolStack(Configurator.java:129) at org.jgroups.stack.ProtocolStack.startStack(ProtocolStack.java:402) at org.jgroups.JChannel.startStack(JChannel.java:1614) ... 95 more Caused by: java.net.SocketException: Cannot assign requested address at java.net.PlainDatagramSocketImpl.socketSetOption(Native Method) at java.net.PlainDatagramSocketImpl.setOption(PlainDatagramSocketImpl.java:309) .......... The Informatica KB's along with other articles on the web point to passing the following parameter to the run.sh file:- -Djava.net.preferIPv4Stack=true. This however, did not resolve the issue for us the problem however got resolved when the JBOSS engineer also added the following setting:- -Djboss.partition.udpGroup=*.0.0.* -Djboss.partition.name=HUBDEV -Djboss.messaging.ServerPeerID=1 A situation that does not arise often, so worth recording on the logs to remember later. While working on various data warehousing or batch jobs I have pondered, ran proof of concept projects for evaluating job scheduling tools, and implemented jobs so that they could be run in minimal time utilizing all the resources available in the execution environment while avoiding pitfalls like excessive parallelism. I have come up with some observations/ideals/requirement in this area, as described below.
Since we could use the operators available from the SQL provided in my previous post from Informatica, it could be translated easily into an Informatica map. The attached diagram is self explanatory. The SQL override specifies a sort order by col1. To get a predictable output every time with same data in the table, it could be sorted on col1 & col2 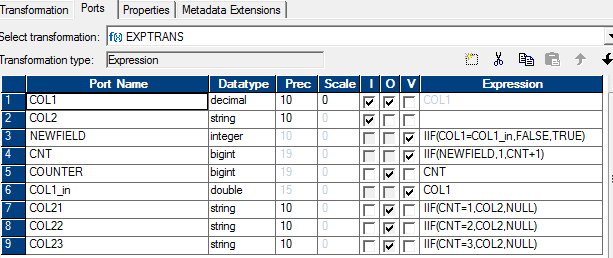  There won't be many times, but sometimes you may need to drop/recreate indexes on the CMX_ORS tables to typically re-import data. The following code PL/SQL code snippets shows how to do it.
Dropping Indexes CREATE OR REPLACE PROCEDURE drop_ors_indexes( in_table_name IN VARCHAR2) AS ddlText VARCHAR2(1000); CURSOR constraint_ IS SELECT t.table_name, replace(trim(k.rowid_key_constraint,'.','_')) rowid_key_constraint FROM C_REPOS_TABLE t, C_REPOS_KEY_CONSTRAINT k ON ( t.rowid_table = k.rowid_table AND t.table_name = in_table_name) WHERE EXISTS ( SELECT 1 FROM USER_INDEXES u WHERE u.INDEX_NAME = replace(trim(k.rowid_key_constraint,'.','_')); BEGIN FOR rec IN constraint_ LOOP ddlText := 'DROP INDEX '||rec.rowid_key_constraint; execute immediate ddlText; END LOOP; END drop_ors_indexes; / Re-creating indexes CREATE OR REPLACE PROCEDURE create_ors_indexes(in_table_name IN VARCHAR2) AS Left as an exercise for the reader to create based on drop indexes. You would need to use C_REPOS_KEY_CONSTRAINT_COL to use the columns for the index. Tablespace name is also available from the C_REPOS_TABLE. BEGIN END create_ors_indexes; / |
About Sarbjit ParmarA practitioner with technical and business knowledge in areas of Data Management( Online transaction processing, data modeling(relational, hierarchical, dimensional, etc.), S/M/L/XL/XXL & XML data, application design, batch processing, analytics(reporting + some statistical analysis), MBA+DBA), Project Management / Product/Software Development Life Cycle Management. Archives
March 2018
Categories
All
|
 RSS Feed
RSS Feed