|
SSD made it on the data scene more than a decade ago, and was, e.g. used in one of my (then) organization's database storage tier for MySQL. But the promise of SSD was not really realized as the access mechanisms for SSD were still bottle-necked by traditional storage protocol stacks, controllers, etc. There was plenty of acknowledgement of the need for the software mechanisms to change to go along with that theme. With recent bump is the RAW IOPS, Sequential throughput, and lowering of latency; it seems that there would be little more excitement left on that front(i.e. hardware) especially with latency getting to around 10 microseconds and a lot more of protocol stack work getting done. To me the more exciting frontier is being met by NVM express protocol design which shows how with lower CPU utilization more data could be consumed (following is used as is from nvmexpress documents. The next wave of nvmexpress over fabrics would make its case for scaling out storage. With this in mind and a demo rig build, starting the exploration into figuring out the optimal for data transformation, storage and analytics. Watching out for pioneering vendors e.g. Tegile or PureStorage providing SSD hardware which is utilizing these optimizations. 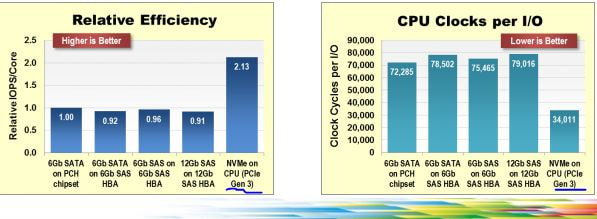 Strange isn't it? that, it should take more than a decade to get to doing the things done right way? Its a rhetorical question, (strange part), of course. But, with vision and support it could have been done from get go, so what do you think went missing?
0 Comments
The following images show the reading from various benchmarks. Mostly as expected, though the setting changes (Rapidmode ON/OFF) with Samsung Magician are a bit surprising. INTEL P900 - Optane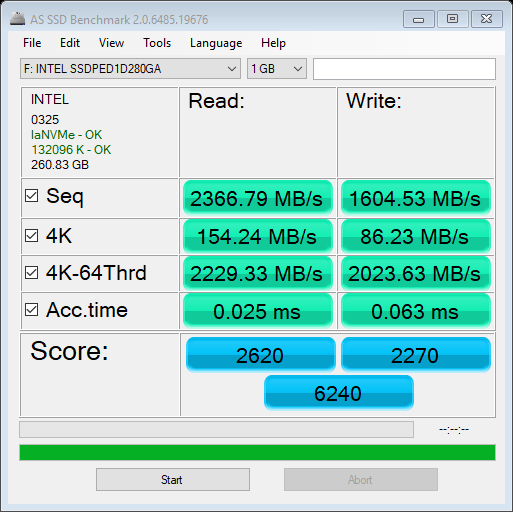 Samsung 960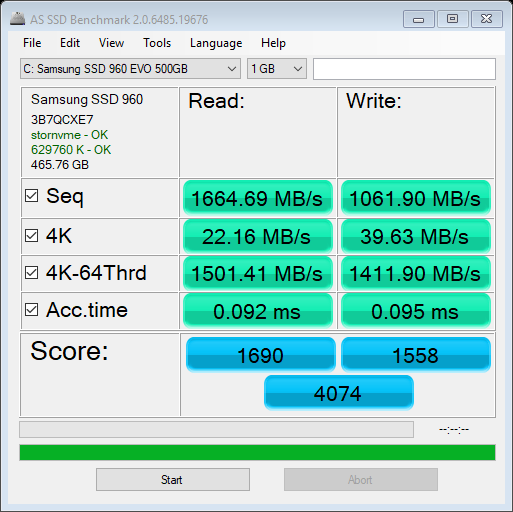 Samsung 850 ssd - Without rapidmode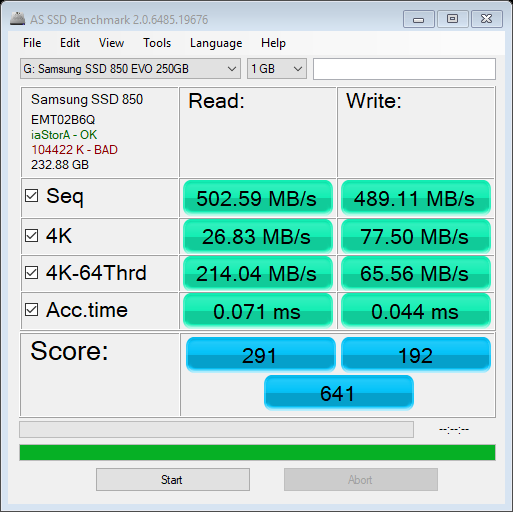 SAMSUNG 850 SSD - WITH RAPIDMODE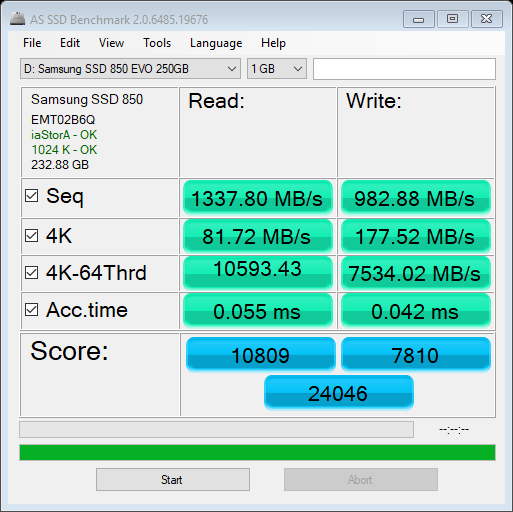 So the rapid mode setting made a change which seems to make a difference from even the fastest Optane, so next thing would be to find out its relevance to data processing SanDisk ssd - external - usb 3.1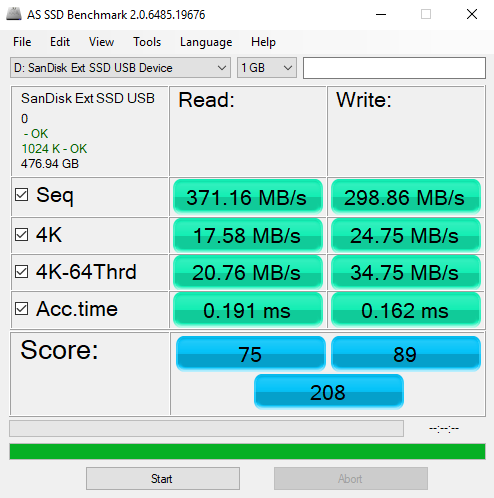 Recently, I got a "memo" that the code that I have shared here was probably done on a company's time. Well, none of the code developed here was "first" done on any company's time. Most of the code does not reveal any trade secrets of vendors, et. al., either. It was available for various other reasons on the various forums, I decided to put together things to showcase other usages. The "secret sauce" of integrating them is, if any, sort of, provided through comments, but without sharing the code, which would have made any of the companies successful. I usually can't stand the code I wrote, so I end up making it different next time hoping to make it better. Some of the themes have been around for ages, its just bringing them to a certain context. So relax, your competitive edge is not going blunt because of this website. It just is a way to pay forward that I got from others to make "the company's" needs met.
Oh, also, please use anything provided here with the explicit understanding that nothing is warrantied to work for you, your mileage may vary, and so on so forth... |
About Sarbjit ParmarA practitioner with technical and business knowledge in areas of Data Management( Online transaction processing, data modeling(relational, hierarchical, dimensional, etc.), S/M/L/XL/XXL & XML data, application design, batch processing, analytics(reporting + some statistical analysis), MBA+DBA), Project Management / Product/Software Development Life Cycle Management. Archives
March 2018
Categories
All
|
 RSS Feed
RSS Feed